Artificial Intelligence and Hold’em, Part 2: Clustering & “Solving” Heads-Up Hold’em


Poker pro and software developer Nikolai Yakovenko continues his three-part series examining how far researchers have gotten in their efforts to build a hold’em playing AI system.
According to my buddy Justin, classification and its cousin regression are essentially a science, while clustering is more of an art.
Many of us are familiar with classification and regression problems. Will the dollar go up or down against the euro? Which horse should I back in the next tournament? Is it better to raise, call, or fold in this position, or should I mix it up? There is an objective that you’d like to maximize, and there is a science to maximizing that objective, even if we might disagree what that objective should be.
That last part is not a trivial matter. Coming up the poker ranks in the mid-2000s, I thought the objective in poker was to win the most money, while giving the most action. In our underground New York games, you would get banned if you didn’t play enough hands. It was understood that anybody could break even simply by playing tight, and there was no room that guy.
It goes without saying that nobody in these games was playing game theory optimal poker — that wasn’t the objective. Regulars came to the games to blow off steam after work, and every chip was in play. You were allowed to win if you could, but you had to give action.
Classification tasks are rarely as clear. Given a group of students, who did enough to pass? Which student’s college application should be accepted, and who should be wait-listed? Which players deserve to be inducted to the Baseball Hall of Fame? These aren’t arbitrary decisions, and some of them can be very important. Yet for classification tasks, there is not an objective measure that we can all understand or agree upon.
Results are often measured by a post-hoc analysis on the indirect outcomes, made further down the chain. Our admissions system is great — just look at all of our successful alumni! Grades are whack — after all, Albert Einstein got terrible grades and former Virginia Governor Douglas Wilder finished dead last in his Howard University class. There’s also the “LGTM” (looks good to me) measure. How good is your Hall of Fame classifier? Does the selection criteria put all of the obvious HOFers on the right side of the line, and all the obvious non-HOFers on the other side? If so, I’ll keep listening. With non-obvious borderline cases, it’s going to be a case of classification by LGTM.
As we talked about in Part 1, counter-factual regret minimization (or CFR) is a scientific process for finding a Nash equilibrium in a heads-up poker game. Scientists have shown that it can get within 1% of a perfectly unexploitable strategy in heads-up limit hold’em. It’s also at the core of the best heads-up NLHE AIs to date.
The science part is about iteratively solving for this unexploitable equilibrium. However since hold’em contains too many game states to apply the science directly, we first need to group together ”similar” hands, both preflop and after the flop, so that the CFR can be applied to a much smaller problem. In other words, what we have here is an especially challenging classification task.
Enter “clustering.”
The Art of Clustering
If you’re going to group hands together and come up with a common betting policy for each group, it helps if the groups make some kind of poker sense. This is where ”looks good to me” thinking comes in. How about grouping hands together by their all-in value against a random hand? (Sure, looks good to me.) But that means I’m grouping drawing hands together with small pairs. Why don’t we square the all-in values on the river before we average them, so that drawing hands are artificially inflated? (Okay... not really following you there, but looks good to me.) And so on.
Clustering by hand strength on every street worked well for the first version of CFR in 2007. A nice advantage to using a hand-value estimate is that it’s easy to put hands in different buckets simply by sorting. You know that a lot of hands will be about 50% to win against a random opponent, on a random board. That’s a 0.50 value. Most hands will fall between 0.40 and 0.60 on most boards. If you’d like to split these hands into 10 buckets, the top one might be those with 0.99 to 0.80 value, the next one 0.80 to 0.72, and so on. This is crude, and very different types of hands might end up in the same bucket, but it works pretty well. It certainly works better than playing all of the hands according to the same policy.
Eventually better clustering for similar hands was developed, which seem to capture the similarities between poker hands in a comprehensive way that a human poker players might understand. The essence of this approach was to look at the distribution of outcomes for a given hand, not just the average return — i.e., made hands compared to drawing hands, that sort of thing.
Two probability distributions can be compared with the “Wasserstein metric,” commonly known as the earth mover’s distance. It’s pretty intuitive. Consider the preflop hands 4x4x and Jx10x-suited. These two hands have the same all-in win rate against a random hand — about 57%. But as a poker player, you know that these two hands get to that 57% in different ways. It’s easy to see the difference in graph form, by plotting the number of full boards against which both hands win 5% of the time, 20%, 50%, and so on:
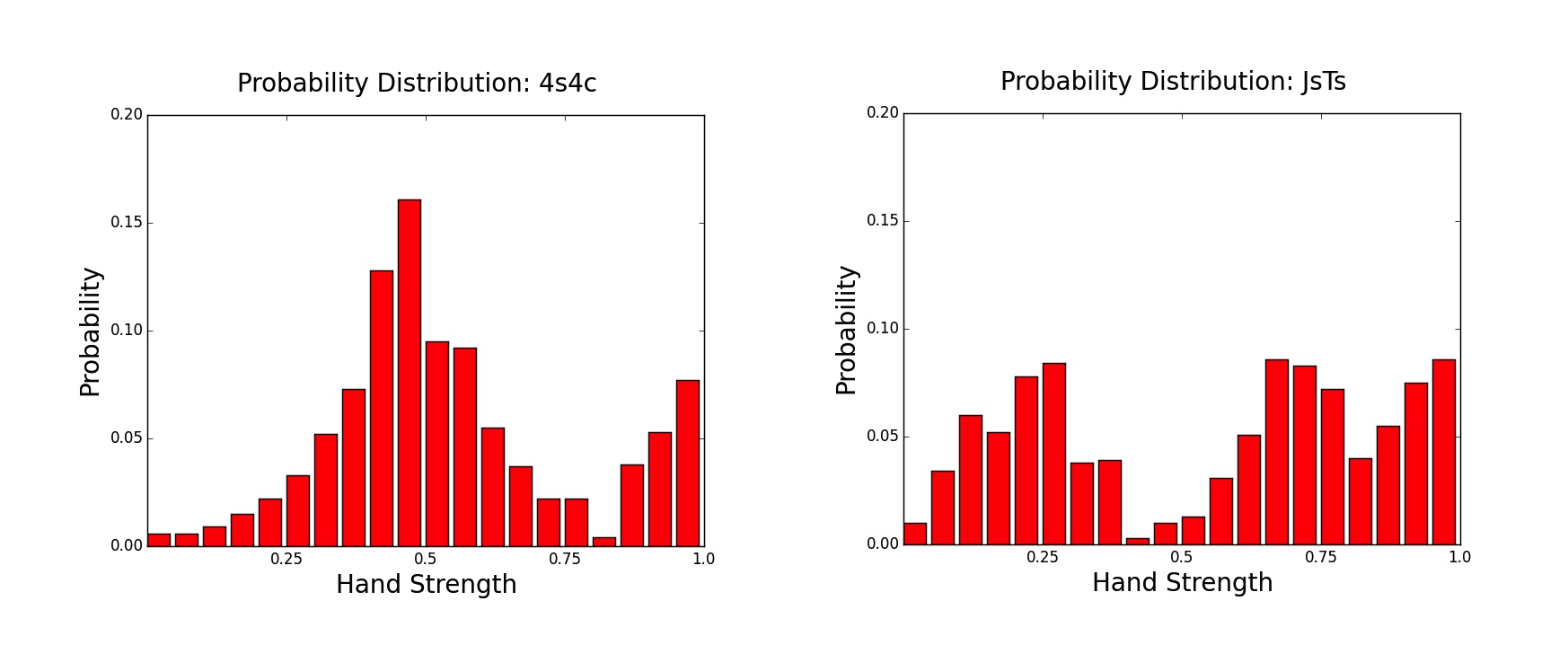
As you can see, the 4x4x preflop hand wins against 40% to 60% of opponents on most rivers. You’re on the good side of a flip. On the other hand, Jx10x-suited wins less than 40% against many hands, but it also grabs a 70% to 90% win rate on many other rivers. There are actually very few 40% to 60% win rates for Jx10x-suited on the river.
The earth mover’s distance measures how much ”work” it takes to move one graph into the other graph — in other words, how much probability mass must be shifted to get from graph A to graph B (as the above images illustrate). By the earth mover’s distance, it’s easy to see that while 4x4x and Jx10x-suited have the same average all-in value, they are far from the same hand.
It’s a neat trick, the way earth mover’s distance seems to capture the difference between drawing hands and made hands, as well as how vulnerable hands differ from those with a steady chance of winning. By comparing hands in two dimensions (all-in value and earth mover’s distance), it’s possible to organize hands by similar, or similar-enough categories, without explicitly looking for poker patterns like flush draws, middle pairs, or “action flops.”
In order to make logical buckets on any street, we can group hands that are close to each other by earth mover’s distance, by average all-in value, or by using a combination of the two. The chart below shows all 169 possible preflop hands, grouped into eight clusters by earth mover’s distance:
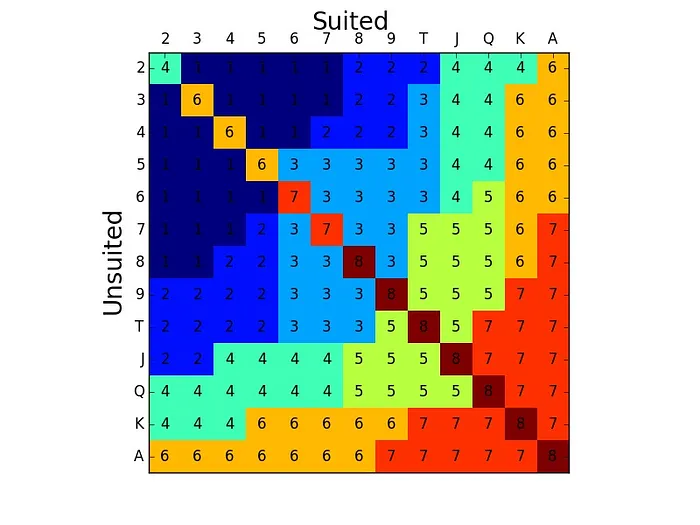
Here are those eight clusters sorted out into list form:
- hands with two unpaired cards below an 8x
- non-connected hands that are Jx-, 10x- or 9x-high
- connected or suited middle cards
- weak hands with a Broadway card and 2x2x
- remaining Broadway hands, and hands like 10x9x-suited
- weak aces, weak kings, and small pairs
- big aces, big kings, suited Broadways, and medium pairs
- big pairs (8x8x+)
Some of the group boundaries might look a bit arbitrary, but the groups generally make sense to me as a poker player. It’s also nice to see such groupings created by a mathematical process, rather than with rules written by hand. While it’s much harder to see what this process looks like on the flop, it’s reasonable to suppose that it might produce a preflop strategy that also makes sense. That said, you’d obviously want to use a lot more than eight buckets over all postflop combinations.
The best bucketing strategy using no more than 50 million bucketing information sets (which you could reasonably run on a fast modern computer), includes 169 buckets for each preflop hand, 9,000 buckets on the flop, 9,000 buckets on the turn, and 9,000 buckets on the river. These groups were calculated from a mix of the earth mover’s distance and average all-in values against random opponent hands. Once the groupings are established, it’s just a matter of running the CFR equilibrium-finding algorithm over all canonical boards, and pushing the regret from each hand into its assigned bucket.
After CFR runs for a few days (or a few weeks), it will produce a near-equilibrium strategy, with a betting policy for each bucket. Just sit back, and watch the algorithm’s exploitability bounds go down from bet-sized noise, to something less than 1/10 of a big blind per hand, even against a perfect opponent.
Applying the equilibrium to a real game is then as easy as looking up the bucket for your current hand, and flipping a coin if the recommended strategy recommends mixing two or more actions.
Approaching a Limit Hold’em “Solution”
When I learned that heads-up limit hold’em can be solved by a simulation and a few equations, I was excited. But then I became kind of sad.
Although limit hold’em has not been solved as cleanly as games like checkers or Connect Four, the CFR solution to LHE is bit closer to the ones for those games than something like a chess engine. Computers play chess better than any human, but this is largely because they can calculate for positions that haven’t been seen before, they can thoroughly (and quickly) search through possible moves for positions that have been seen, and for opening moves they can quickly find if it has ever occurred in a grandmaster game.
There are still phases of chess where humans outthink computers, and given a tough middle-game position, the computer still has to simulate all of the choices from scratch. It can try an instant lookup, but those evaluations are not close to human strength. On the other hand, an advanced C++ student could write a program that solves checkers or Connect Four, instantly providing a strategy for every possible board position, with little to no online search required. Solutions for heads-up limit hold’em are getting closer to this category.
Visiting 3.2 billion game states takes a while, but it’s possible. And it turns out that every bucketed group of game states can be solved as a sub-problem, in a fairly straightforward way, by simulating opponents’ best responses and calculating the regret of removing options from the AI’s strategy mix.
This is impressive, but it does not resemble artificial intelligence. I guess this is what makes me sad. A chess computer outplays humans by efficiently searching through all possible outcomes, a dozen moves away. It’s sitting there, thinking about the possibilities. Meanwhile the CFR-based limit hold’em approaches an unexploitable solution by solving the entire game with a set of equations, or rather, solving a game that’s smaller, but close enough to real hold’em.
CFR is an amazing piece of math. It’s also a little bit unsettling that this algorithm, which can be applied to any turn-based game theory problem, happens to solve a game that some of us were proud to play very well, and from which a few of us made a living. And it does so within 1% of perfectly balanced play, seemingly gaining much insight into the internal logic of the game.
Putting it another way, it’s impressive that CFR can consider every possible board and every possible response from its heads-up opponent, including moves that would never happen in a real game. At the same time, it’s a little discouraging to think that it spends so much time looking at possibilities that will never happen.
Whatever poker intelligence is embedded in the system, it seems like most of it goes into bucketing the hands along logical boundaries, along with the clever tricks used to simulate an opponent’s CFR best-response quickly (which I didn’t get a chance to get into here). Once that’s done, the action policies are just a table lookup, as if your computer AI was playing off of a blackjack chart.
Next time we’ll conclude our discussion with a closer look at where things presently stand with regard to developing a no-limit hold’em-playing AI, and we’ll also try to imagine what a strong NLHE AI might eventually look like.
For more about the research discussed here, check out the original 2007 paper from the University of Alberta team and their more recent one from 2013 (from which come data for the graphs appearing above). Thanks to all of the researchers at the University of Alberta, Carnegie Mellon University, and elsewhere who created these systems and make them available for anyone to learn from, free of charge.
Image (foreground): “Artificial Intelligence,” Alejandro Zorrilal Cruz. Public domain.
Nikolai Yakovenko is a professional poker player and software developer residing in Brooklyn, New York who helped create the ABC Open-Face Chinese Poker iPhone App.
Want to stay atop all the latest in the poker world? If so, make sure to get PokerNews updates on your social media outlets. Follow us on Twitter and find us on both Facebook and Google+!









